09 Dec 2021
As of December 2021, these features have been implemented: stadard procedure NEW applied to record parameters; relational operator IS applied to record types; and function procedure SYSTEM.TYP applied to pointer variables and record/record pointer types:
TYPE T = POINTER TO EXTENSIBLE RECORD END;
Ext = POINTER TO RECORD (T) END;
VAR p: T;
x: LONGINT;
BEGIN
NEW(p);
IF p IS Ext THEN x := SYSTEM.TYP(Ext) ELSE x := SYSTEM.TYP(T) END;
x := SYSTEM.TYP(p);
END
Of course, NEW is not implemented by the compiler, but rather by the run-time environment mandated by the Language Report. What the compiler does is transform NEW(p) into calls to a procedure of the following quasi-signature:
NEW = PROCEDURE (tag: ADDRESS): T;
where *tag *is the address of the type descriptor of the formal type of p, i.e. T. Thus, the compiler performs the following transformation:
NEW(p) => p := @Kernel.NewRec(SYSTEM.TYP(T))
The peculiarity is that subject module containing NEW(p) does not have to import Kernel explicitly, and cannot import Kernel implicitly: in a particular system, the procedure implementing NEW(p) may be defined in an arbitrary module. The linking is done at module load time by the loader. So, the compiler has to provide data for the linking loader to be able to perform the linking. The format of this data has changed in the updated OCF format, as has the format of all data defining imports and import fixups in the machine code and module metadata.
The other novelty is that imported types’s descriptor addresses have to be entered at link time into the PROXY table. Thus the PROXY table now holds addresses of imported procedures and imported types’ descriptors. Unlike imported procedures, imported types may be referenced not only from machine code (which is done as a RIP-relative addressing into PROXY), but also from the module’s metadata. This means that the linker has to not only place the imported type’s descriptor address into the PROXY table, but also fixup all references to this type descriptor from the metadata. And the compiler has to chain all references to each imported type.
The testing environment in A2 was made capable of linking against ‘platform interface modules’, much like module WinApi allows to use WinApi calls in BlackBox modules. A module ProtoKernel (compiled by Herschel) imports a platform module and calls a primitive memory allocation procedure in order to provide the NewRec procedure. Thus a module M (compiled also by Herschel) may use NEW, IS and SYSTEM.TYP. The linking loader in the testing environment performs all the work for M to be loaded and executed. This testing environment might in the future become a prototype for BlackBox running on top of A2.
Appropriate tests have been added to the project.
The A2 tester allowing to allocate dynamic variables makes way to further development of Herschel and implementation of other features related to dynamic memory and type extension.
04 Aug 2021
After a 4-month break (which was used to work on BlackBox 2.0) I went back to Herschel and picked it up where I left it off - at NEW.
For NEW to work, the run-time environment has to provide some metainformation. In BB/CP, this metaiformation is in the form of type descriptors whose addresses can be obtained with SYSTEM.TYP(T), as well as many other bits and pieces defined in Kernel (Kernel.Type, .ObjDesc, .Directory, .Module, etc.). Also, NEW(RecPtr) is translated into a call for PROCEDURE Kernel.NewRec(descriptor: ADDRESS): ADDRESS.
It turns out this metainformation, including type descriptors, is formed by the compiler and written out directly into the OCF format. The module loader then loads the OCF format, applies various fixups - and voila, the metainformation is ready for the Kernel to use.
Because it contains a lot of pointers, and pointer size grows from 4 to 8 bytes, a lot of amendments had to be applied to the compiler and some to the module loader (in the testing environment).
At this time, SYSTEM.TYP(T) has been implemented, and a test has been developed that demonstrates that record type descriptors, field directories and applicable fixups work well in the complier, in the OCF format and in the module loader.
NEW is on the way.
10 Apr 2021
* Most language features save type extension and pointers handling implemented.
* A downloadable package for Windows, here, easy to run and try out Herschel features.
* The binder tool now capable of producing a DLL out of an OCF module (that is, one compiled Component Pascal module)
* Compiler capable of adhering to Microsoft calling convention (mark your procedures with [ms64] sysflag)
* Produced DLL (with some language features) tested successfully in Excel VBA environment
For further compiler development, an improved testing environment is necessary (at least desireable) that could link a tested module with a proto-kernel - a trivial run-time environment that provides the NEW procedure implementation. After some consideration, we have decided to continue building on the A2 testing environment. Now, a trivial linking module loader has been implemented that runs in A2/Linux64. With this, we will be working on type extension, dynamic variables and pointer handling.
As side effects:
* Further improvements in the OCF decoder, making decoded OCF modules easier to understand and proof-read.
* Feeling VERY uncomfortable with the A2 user experience, built a simple tool that enables A2 source editing in BlackBox (including use of all text attributes), compilation in A2’s Fox compiler, with error messages brought back into convenient BlackBox error markers.
28 Jan 2021
Allrighdee, there’s alot of news since the last update.
* ELF (Linux) and PE (Windows) executables are produced from 1 module, allowing host system binding (calls to host os). This enables ‘Hello world’ applications on both host platforms. Exciting stuff!
* This implies the two host calling conventions (SysV and MS x64) have been implemented as well. This is a huge amount of work!
* Both sides of the calling conventions have been implemented - this means that you can call a procedure of the convention AND write your own procedures of those conventions. This is necessary for host callback procedures in BlackBox - and for clients that want to make, say, DLLs in BlackBox with procedures that can be called by C/C++/arbitrary programs.
* PE DLLs can be made of 1 module. Lots of work here!
* IF, WHILE, REPEAT, RETURN, FOR implemented. This was maybe one of the simplest parts of the work done.
* REAL and SHORTREAL arythmetic added. It uses the inherited x87 implementation. Limited use of XMM unit is implemented to allow interaction with MS x64 calling convention.
As a side-effect:
* Improved OCF decoder and disassembler, using some advice from user X512.
* A module providing convenient scanners for the OCF format is under construction. May be of use in other system-level programs.
14 Nov 2020
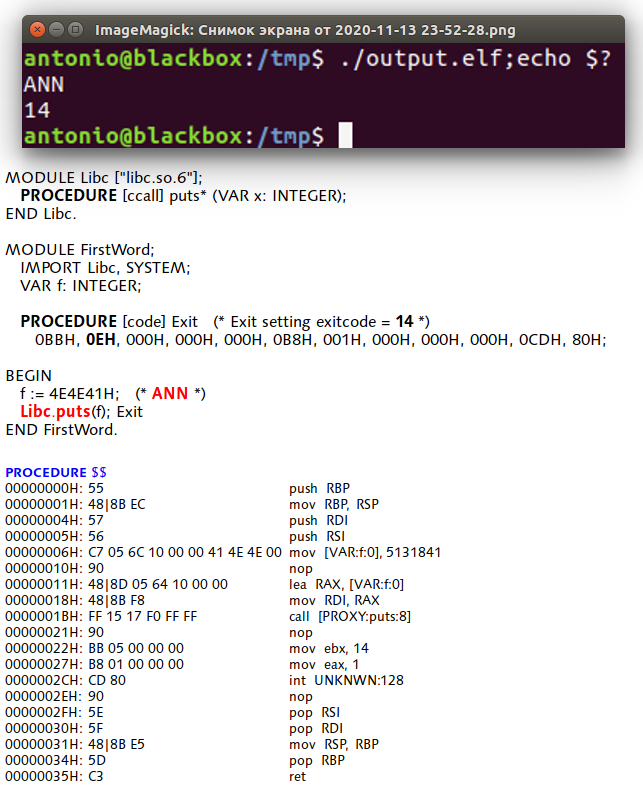
After weeks of hard work (understanding and adapting the OCF format, then hacking the ELF format), I have got Herschel to produce a module that imports a host library (.so) and then to link it into an ELF executable. Upon invocation, it is linked (by the operating system) to the libraries, after which it prints it’s first 3-letter word - Herschel’s first word to the world.
The example below calls libc’s *puts() *function. Calling an external library implies using the appropriate calling convention - in this case, System V ABI calling convention. For those of our readers who are not in the know - it is WAY more complicated from a compiler writer’s perspective than the good old [ccall] convention, and CP2’s native convention. I had to implement parts of it.
As you can see in the example below, I also had to implement (partially) the [code] procedures in order to exit() from the host os process gracefully - it is done thru an interrupt call.
Another major bulk of work I had to do - the OCF file format. Herschel now outputs OCF files; they cannot be read by the 32bit BlackBox because I had to add two fields to the format to provide support for 64-bit System V ABI. At first it seemed rather compilcated, but now, ‘on the other side of the hill’, I would say OCF is reasonable, purpose-driven, resource-savvy, beautifull and minimalistic. To learn and adapt it, I produced an OCF importer - somewhat more detailed than the one shipped with BlackBox. One feature I’m particularly happy with is decoding variable and procedure names in the disassembly of the module text.
Quite a mountain of work since the last status update! Now - on to PE format, so that our Windows-based users could write their own first words in 64-bit BlackBox!
Thank you to the donors who help do this work.
If you’re interested in having a 64-bit CP compiler and BlackBox, get invested in it as well - consider donating to the project in order to support it.